User guide: run the Bayes Point estimators¶
The package offers a user-friendly interface to run the Bayes Point estimators on a given dataset.
You can choose between the following estimators:
FindRsClassifier: uses an iterative strategy to build a number of bins that correctly classify the data, attempting to build the most specific rules, while not contradicting existing examples.RIPPERClassifier: uses the RIPPER algorithm to create a set of rules.Id3Classifier: uses the ID3 algorithm to fit the data, and synthesizes a ruleset by walking each path of the grown tree.AqClassifier: uses the AQ algorithm to find a ruleset that is the most general, while not contradicting existing examples.
You can import them as follows:
>>> from bpllib import FindRsClassifier
>>> from bpllib import RIPPERClassifier
>>> from bpllib import Id3Classifier
>>> from bpllib import AqClassifier
Once imported, you can use them as any other scikit-learn estimator. For example, you can fit a model on a dataset as follows:
>>> from sklearn.datasets import load_iris
>>> X, y = load_iris(return_X_y=True)
>>> clf = FindRsClassifier()
>>> clf.fit(X, y)
Each classifier in this package can be instanced with a set of parameters.
For example, you can set the T and the strategy parameters of the FindRsClassifier as follows:
>>> clf = FindRsClassifier(T=20, strategy='bp')
Use strategy parameter to choose between the following strategies:
bpfor the Bayes Point strategybofor the Bayes Optimal strategybest-kfor selecting the bestkrulesNonefor the default strategy (requiresTset to1)
Using T>1 requires more time, as the algorithm will run T times.
The bo strategy is the least interpretable, since it will yield many (duplicate) rules.
The bp strategy is more interpretable, since it will yield a smaller number of rules.
The best-k strategy is the most interpretable, since it will yield a number of rules selected by the user.
Fitting¶
The fit method of each classifier takes as input the dataset X and the target y. The dataset X is a numpy array of shape (n_samples, n_features) and the target y is a numpy array of shape (n_samples,).
The fit method returns the classifier itself.:
>>> from bpllib import get_dataset, FindRsClassifier
>>> from sklearn.model_selection import train_test_split
>>> est = FindRsClassifier()
>>> X, y = get_dataset('TTT')
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
>>> est.fit(X_train, y_train)
Predicting¶
The predict method of each classifier takes as input the dataset X and returns the predictions y_pred of the classifier. The dataset X is a numpy array of shape (n_samples, n_features) and the predictions y_pred is a numpy array of shape (n_samples,).
The predict method returns the predictions y_pred of the classifier.:
>>> from sklearn.metrics import f1_score
>>> y_pred = est.predict(X_test)
>>> print(f1_score(y_test, y_pred))
Inspecting the classifier¶
The focus for the bayes-point-learning package is to create white-box classifiers, in order to increase interpretability, explainability, and transparency. Therefore, the classifiers in this package can be inspected to check out the rules found by the classifier.
You can check out the rules found by a classifier with T=1 by using the rules_ attribute. This is a list of Rule objects.:
>>> est.rules_
You can check out the rules found by a classifier with T>1 by using the rulesets_ attribute. This is a list of lists of Rule objects.:
>>> est.rulesets_
Old¶
Estimator¶
The central piece of transformer, regressor, and classifier is
sklearn.base.BaseEstimator. All estimators in scikit-learn are derived
from this class. In more details, this base class enables to set and get
parameters of the estimator. It can be imported as:
>>> from sklearn.base import BaseEstimator
Once imported, you can create a class which inherate from this base class:
>>> class MyOwnEstimator(BaseEstimator):
... pass
Transformer¶
Transformers are scikit-learn estimators which implement a transform method.
The use case is the following:
at
fit, some parameters can be learned fromXandy;at
transform, X will be transformed, using the parameters learned duringfit.
In addition, scikit-learn provides a
mixin, i.e. sklearn.base.TransformerMixin, which
implement the combination of fit and transform called fit_transform:
One can import the mixin class as:
>>> from sklearn.base import TransformerMixin
Therefore, when creating a transformer, you need to create a class which
inherits from both sklearn.base.BaseEstimator and
sklearn.base.TransformerMixin. The scikit-learn API imposed fit to
return ``self``. The reason is that it allows to pipeline fit and
transform imposed by the sklearn.base.TransformerMixin. The
fit method is expected to have X and y as inputs. Note that
transform takes only X as input and is expected to return the
transformed version of X:
>>> class MyOwnTransformer(BaseEstimator, TransformerMixin):
... def fit(self, X, y=None):
... return self
... def transform(self, X):
... return X
We build a basic example to show that our MyOwnTransformer is working
within a scikit-learn pipeline:
>>> from sklearn.datasets import load_iris
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.linear_model import LogisticRegression
>>> X, y = load_iris(return_X_y=True)
>>> pipe = make_pipeline(MyOwnTransformer(),
... LogisticRegression(random_state=10,
... solver='lbfgs'))
>>> pipe.fit(X, y)
Pipeline(...)
>>> pipe.predict(X)
array([...])
Predictor¶
Regressor¶
Similarly, regressors are scikit-learn estimators which implement a predict
method. The use case is the following:
at
fit, some parameters can be learned fromXandy;at
predict, predictions will be computed usingXusing the parameters learned duringfit.
In addition, scikit-learn provides a mixin, i.e.
sklearn.base.RegressorMixin, which implements the score method
which computes the 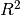 score of the predictions.
score of the predictions.
One can import the mixin as:
>>> from sklearn.base import RegressorMixin
Therefore, we create a regressor, MyOwnRegressor which inherits from
both sklearn.base.BaseEstimator and
sklearn.base.RegressorMixin. The method fit gets X and y
as input and should return self. It should implement the predict
function which should output the predictions of your regressor:
>>> import numpy as np
>>> class MyOwnRegressor(BaseEstimator, RegressorMixin):
... def fit(self, X, y):
... return self
... def predict(self, X):
... return np.mean(X, axis=1)
We illustrate that this regressor is working within a scikit-learn pipeline:
>>> from sklearn.datasets import load_diabetes
>>> X, y = load_diabetes(return_X_y=True)
>>> pipe = make_pipeline(MyOwnTransformer(), MyOwnRegressor())
>>> pipe.fit(X, y)
Pipeline(...)
>>> pipe.predict(X)
array([...])
Since we inherit from the sklearn.base.RegressorMixin, we can call
the score method which will return the score:
>>> pipe.score(X, y)
-3.9...
Classifier¶
Similarly to regressors, classifiers implement predict. In addition, they
output the probabilities of the prediction using the predict_proba method:
at
fit, some parameters can be learned fromXandy;at
predict, predictions will be computed usingXusing the parameters learned duringfit. The output corresponds to the predicted class for each sample;predict_probawill give a 2D matrix where each column corresponds to the class and each entry will be the probability of the associated class.
In addition, scikit-learn provides a mixin, i.e.
sklearn.base.ClassifierMixin, which implements the score method
which computes the accuracy score of the predictions.
One can import this mixin as:
>>> from sklearn.base import ClassifierMixin
Therefore, we create a classifier, MyOwnClassifier which inherits
from both slearn.base.BaseEstimator and
sklearn.base.ClassifierMixin. The method fit gets X and y
as input and should return self. It should implement the predict
function which should output the class inferred by the classifier.
predict_proba will output some probabilities instead:
>>> class MyOwnClassifier(BaseEstimator, ClassifierMixin):
... def fit(self, X, y):
... self.classes_ = np.unique(y)
... return self
... def predict(self, X):
... return np.random.randint(0, self.classes_.size,
... size=X.shape[0])
... def predict_proba(self, X):
... pred = np.random.rand(X.shape[0], self.classes_.size)
... return pred / np.sum(pred, axis=1)[:, np.newaxis]
We illustrate that this regressor is working within a scikit-learn pipeline:
>>> X, y = load_iris(return_X_y=True)
>>> pipe = make_pipeline(MyOwnTransformer(), MyOwnClassifier())
>>> pipe.fit(X, y)
Pipeline(...)
Then, you can call predict and predict_proba:
>>> pipe.predict(X)
array([...])
>>> pipe.predict_proba(X)
array([...])
Since our classifier inherits from sklearn.base.ClassifierMixin, we
can compute the accuracy by calling the score method:
>>> pipe.score(X, y)
0...